Ich freue mich, hier ein neues Satellitenbild-Produkt vorstellen zu können, an dem ich seit einigen Monaten gearbeitet habe. Die Entwicklung dieses Produkts wurde von der Geofabrik mitfinanziert. Dort wird man Kacheldienste für Webkarten anbieten, die auf diesem Bild in Kombination mit der Green Marble basieren.
Hintergrund
Die meisten Leser dieses Blogs werden mit der Green Marble vertraut sein – meinem globalen Satellitenbildprodukt, das die hochwertigste verfügbare Darstellung der gesamten Erdoberfläche mit einer Auflösung von 250m bietet. Die Green Marble wird mit einem Pixelstatistik-Ansatz erstellt, d. h. für jeden Pixel des Bildes wird eine unabhängige Analyse aller verfügbaren Beobachtungen durchgeführt, um die Oberflächenfarbe an diesem Punkt zu schätzen. Diese Art von Technik ist sehr beliebt, weil sie einfach zu implementieren ist und die Verarbeitung sehr effizient durchgeführt werden kann.
Diese Methode hat jedoch zwei wesentliche Nachteile:
- Sie erfordert eine beträchtliche Menge an Daten, um zu einem Punkt zu gelangen, an dem das Endprodukt die gleiche oder eine bessere visuelle Qualität aufweist als ein einzelnes Bild guter Qualität. Wie viel das ist, hängt vom verwendeten Algorithmus und seinen Konvergenzeigenschaften ab, und das ist natürlich in den verschiedenen Teilen des Planeten sehr unterschiedlich. Für die Green Marble Version 3 wurden beispielsweise etwa 1 PB an Rohdaten verarbeitet – das bedeutet mehr als 100 kB an Daten pro Pixel.
- Das Ganze skaliert nicht gut mit zunehmender räumlicher Auflösung. Ich habe dieses Thema bereits im Jahr 2018 ausführlicher diskutiert. Dafür gibt es mehrere Gründe, der am einfachsten zu verstehende ist, dass der Inhalt eines Bildes umso flüchtiger wird, je höher die räumliche Auflösung ist, die man betrachtet. Das heißt, je höher die räumliche Auflösung ist, desto weniger gibt es – im Durchschnitt – einen langfristig stabilen Zustand der Erdoberfläche, zu dem die Pixelstatistik konvergieren kann.
Langer Rede kurzer Sinn: Pixelstatistiken funktionieren sehr gut bei einer Auflösung von etwa 250m, wenn man eine große Datenbasis hat, mit der man arbeiten kann. Bei viel höheren Auflösungen funktionieren sie schlecht, selbst wenn man eine große Datenmenge hat (was in der Regel nicht der Fall ist – aber das ist ein anderes Thema). Dies hat verschiedene Unternehmen in den letzten 5-10 Jahren nicht davon abgehalten, erhebliche Ressourcen in den naiven Versuch zu investieren, Pixelstatistiken auf Landsat- und Sentinel-2-Daten anzuwenden – mit den erwarteten mittelmäßigen Ergebnissen.
Die Alternative zur Pixelstatistik für die Aggregation von Satellitenbildern zu einer homogenen Visualisierung größerer Gebiete ist die Verwendung klassischer Mosaik-Techniken, bei denen einzelne Bilder im Wesentlichen in Form eines Flickenteppichs oder Mosaiks zusammengesetzt werden. Wenn Sie eine knappe Definition wünschen: Eine klassische Mosaik-Technik liegt vor, wenn die Farbe an einem beliebigen Punkt des Bildes in den meisten Fällen (a) primär aus einem einzigen Quellbild stammt und (b) die umgebenden Pixel primär aus demselben Bild stammen. Dies ist offensichtlich nicht der Fall bei einem Pixelstatistik-Verfahren, bei dem die Verarbeitung eines Pixels nicht mit der seiner Nachbarn korreliert ist.
Klassische Mosaik-Techniken sind die vorherrschende Methode für die Aggregation von Satelliten- und Luftbildern mit sehr hoher Auflösung und für qualitativ hochwertige Bilder auf der Grundlage von Landsat- und Sentinel-2-Daten. Das Problem dabei ist, dass die Erzielung einer guten Qualität mit diesem Ansatz ziemlich komplexe Verarbeitungstechniken erfordert und es bestimmte Schlüsselschritte gibt, die bekanntermaßen schwer zu automatisieren sind, da die Qualität der Ergebnisse in hohem Maße von einer kompetenten menschlichen Beurteilung der Daten abhängt.
Daher sind die meisten auf Satellitenbildern basierenden Visualisierungen, die klassische Mosaik-Techniken verwenden, entweder von relativ schlechter Qualität (hohe Wolkeninzidenz, schlechte Farbkonsistenz zwischen den Bildern) oder basieren auf relativ alten Daten, da Aktualisierungen kostspielig sind.
Ich selbst produziere seit fast 20 Jahren Bilder mit klassischen Mosaik-Techniken (eine frühe Diskussion darüber finden Sie in diesem Blog im Jahr 2013) und habe die von mir verwendeten Methoden im Laufe der Jahre verbessert und effizienter organisiert. Aber auch für mich war die Handarbeit bisher immer ein wesentlicher Bestandteil bei der Produktion dieser Bilder und deshalb sind Aktualisierungen in der Regel sehr aufwendig. Daher habe ich seit einiger Zeit nach Strategien gesucht, um die verbleibenden manuellen Bearbeitungsschritte bei der Herstellung meiner höher aufgelösten Mosaike zu eliminieren, ohne dabei zu große Qualitätseinbußen hinnehmen zu müssen. Mit Hilfe der Geofabrik konnte ich nun einige dieser Ideen praktisch umsetzen und evaluieren, und die Ergebnisse möchte ich hier vorstellen und diskutieren.
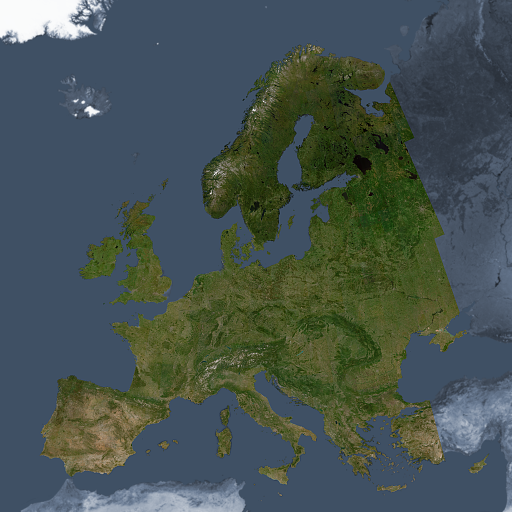
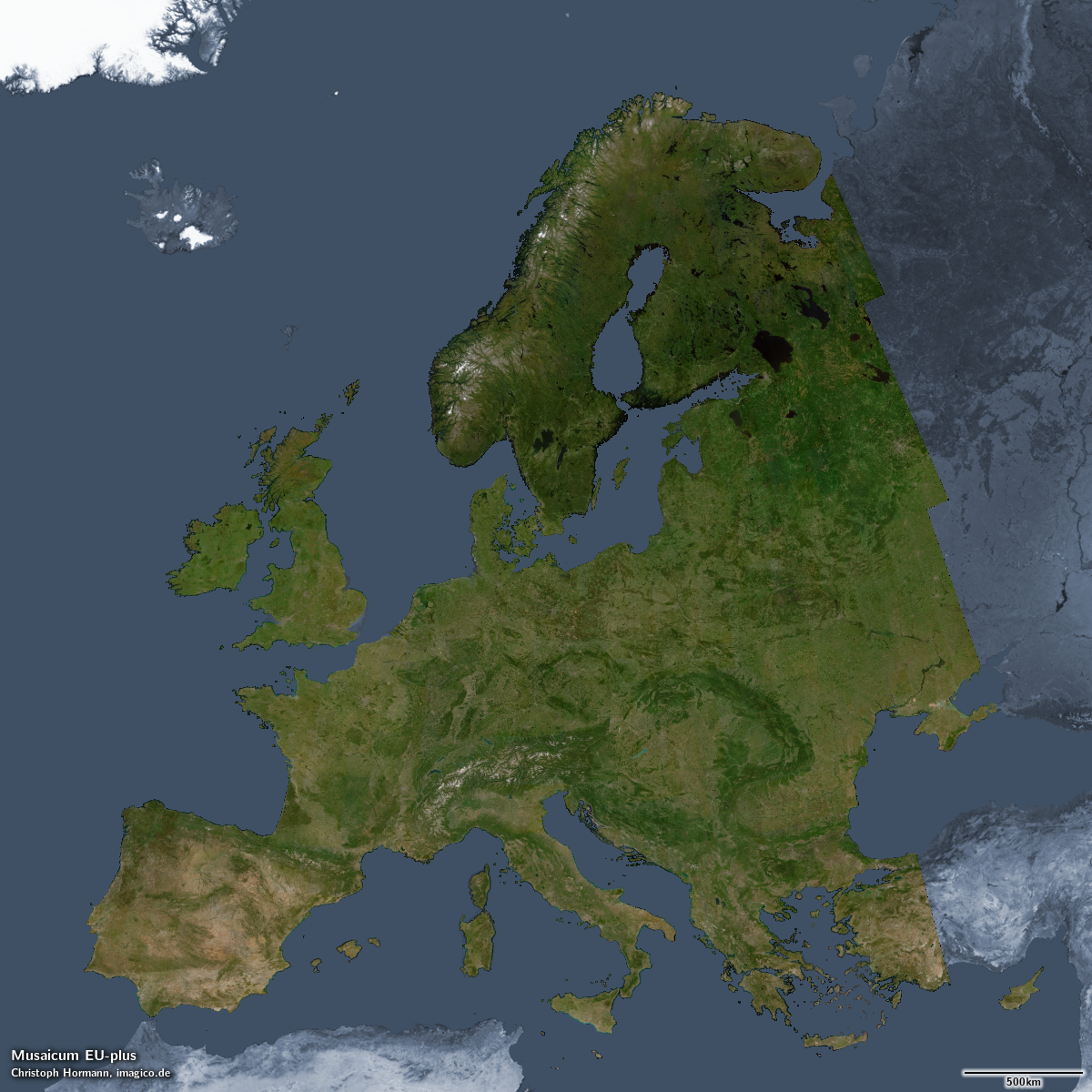
Das Musaicum EU-plus – anklicken für eine größere Version
Das Bild
Bei niedriger Auflösung sieht das Bild der Green Marble sehr ähnlich – was nicht verwunderlich ist, da es mit dem gleichen Ziel erstellt wurde – das lokale Vegetationsmaximum und Schneeminimum darzustellen. Wenn Sie genau hinsehen, können Sie erkennen, dass das Erscheinungsbild nicht ganz so einheitlich ist wie bei der Green Marble – mit einigen Inhomogenitäten, die eindeutig nicht natürlich sind. Dies ist zum Teil auf die geringe Menge der verwendeten Daten zurückzuführen (einfach ausgedrückt: Nicht überall stand im verwendeten Zeitraum ein Quellbild zur Verfügung, das das Vegetationsmaximum exakt repräsentiert). Ein weiterer Grund liegt darin, dass die Datenverarbeitung noch verbesserungswürdig ist – schließlich ist dies ein erster Versuch.

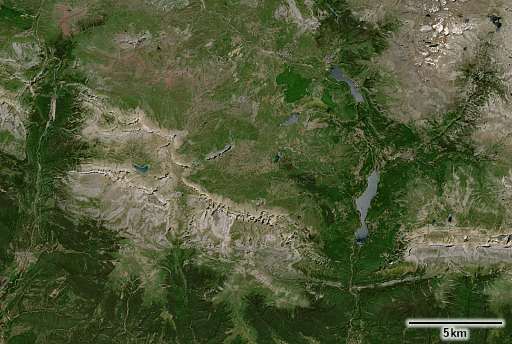
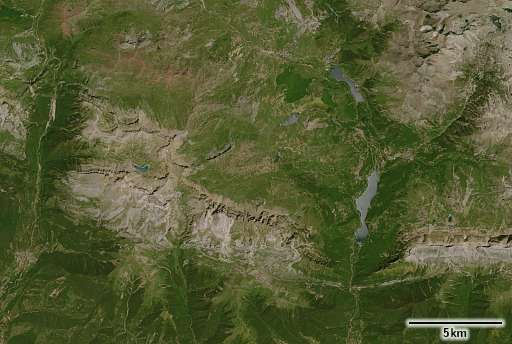
Schweizer Alpen
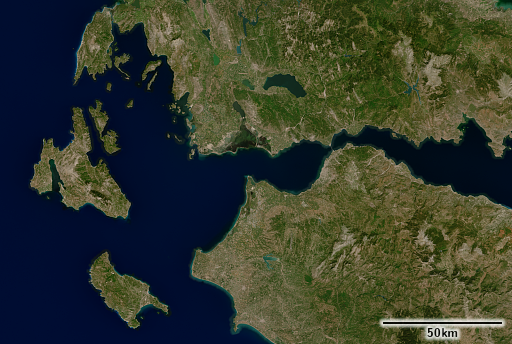
Westliches Griechenland
Wenn Sie sich die Beispielbilder ansehen, werden Sie schnell feststellen, dass es keine Wolken gibt (oder fast keine – bei sehr genauer Betrachtung entdecken Sie vielleicht ein paar, und ja, wenn Sie das gesamte Bild systematisch durchsuchen, werden Sie noch einige mehr finden). Dies ist ein Punkt, an dem die Ergebnisse meine Erwartungen deutlich übertroffen haben. Ich hatte gehofft, einen Wolkenanteil zu erzielen, der wesentlich besser ist als das, was sonst auf dem Markt erhältlich ist, aber ich hatte erwartet, dass er wesentlich schlechter sein würde als bei meinen manuell erstellten lokalen Mosaiken. Das Endergebnis entspricht ziemlich genau den manuell erstellten lokalen Bildern, wobei weniger als einer von 100k Pixeln stark von Wolken betroffen ist. Bei den meisten davon handelt es sich um kleine, isolierte konvektive Wolken.

Vlieland, Niederlande
Der Schwerpunkt des Projekts lag auf der Visualisierung von Landflächen, so dass Wasseroberflächen keine besondere Rolle spielten. Da Gewässer in der Regel ein recht variables Aussehen haben und sich oft nicht in einem strengen saisonalen Muster verändern, sind die Ergebnisse in diesem Bereich nicht immer ideal, vor allem Flüsse ändern ihre Farbe entlang ihres Verlaufs oft recht unregelmäßig. In niedrigeren Breiten, insbesondere bei kleineren Seen, ist auch die Sonnenreflexion ein Problem.

Danzig, Polen

Istanbul, Türkei
Ein paar Worte zu den Daten, die für die Produktion des Bildes verwendet wurden. In Analogie zu den Zahlen, die ich oben für die Green Marble präsentiert habe: Das Volumen der Original-Sentinel-2-Daten, die für dieses Projekt verarbeitet wurden, betrug etwa 20 TB, was bedeutet, dass weniger als 250 Byte pro Pixel benötigt wurden. Das ist extrem wenig, wenn man bedenkt, dass die Menge der Sentinel-2-Daten, die innerhalb eines einzigen Jahres allein für Europa gesammelt wurden, viel höher ist. Eine geringe zu verarbeitende Datenmenge trägt dazu bei, die Verarbeitungskosten niedrig zu halten, und sie ermöglicht auch die Verwendung aufwendigerer Verarbeitungstechniken. Und im Gegensatz zu den Pixelstatistik-Methoden, bei denen das Hinzufügen von mehr Daten immer von Vorteil ist, gibt es bei den klassischen Mosaik-Techniken keinen grundsätzlichen Vorteil, wenn mehr Daten verwendet werden, sondern es geht eher um Qualität als um Quantität.
Eine weitere Herausforderung war, dass ich den Zeitraum, aus dem die Daten stammen, relativ kurz halten wollte. Vorzugsweise nur drei Jahre (2020-2022), bei Bedarf ein weiteres Jahr (2019) und nur in seltenen Fällen werden auch Daten aus 2018 verwendet. In Gebieten, in denen das Erscheinungsbild der Erdoberfläche sehr unbeständig ist – entweder über den jahreszeitlichen Zyklus hinweg oder zwischen den Jahren -, ist es schwierig, homogene Ergebnisse über größere Gebiete zu erzielen.
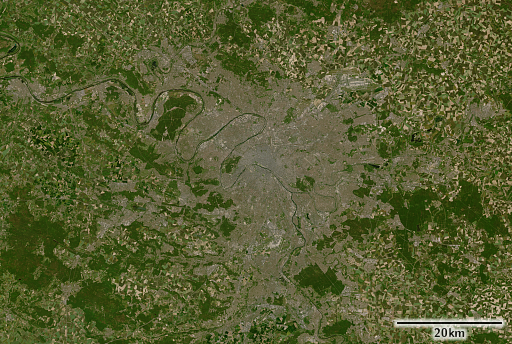
Paris, Frankreich

Cordoba, Spanien
Womit man arbeiten muss
Eines der Dinge, der die Arbeit an diesem Projekt schwieriger gemacht haben, als man naiverweise erwarten würde, ist die schlechte Qualität einiger der gelieferten Daten.
Die Sentinel-2-Daten können in zwei verschiedenen Formen bezogen werden:
- L1C-Daten – das sind die ursprünglichen Top-of-Atmosphere-Reflexionswerte, wie sie vom Satelliten aufgezeichnet wurden
- L2A-Daten – eine Schätzung der Oberflächen-Reflexionswerte auf der Grundlage der TOA-Messungen
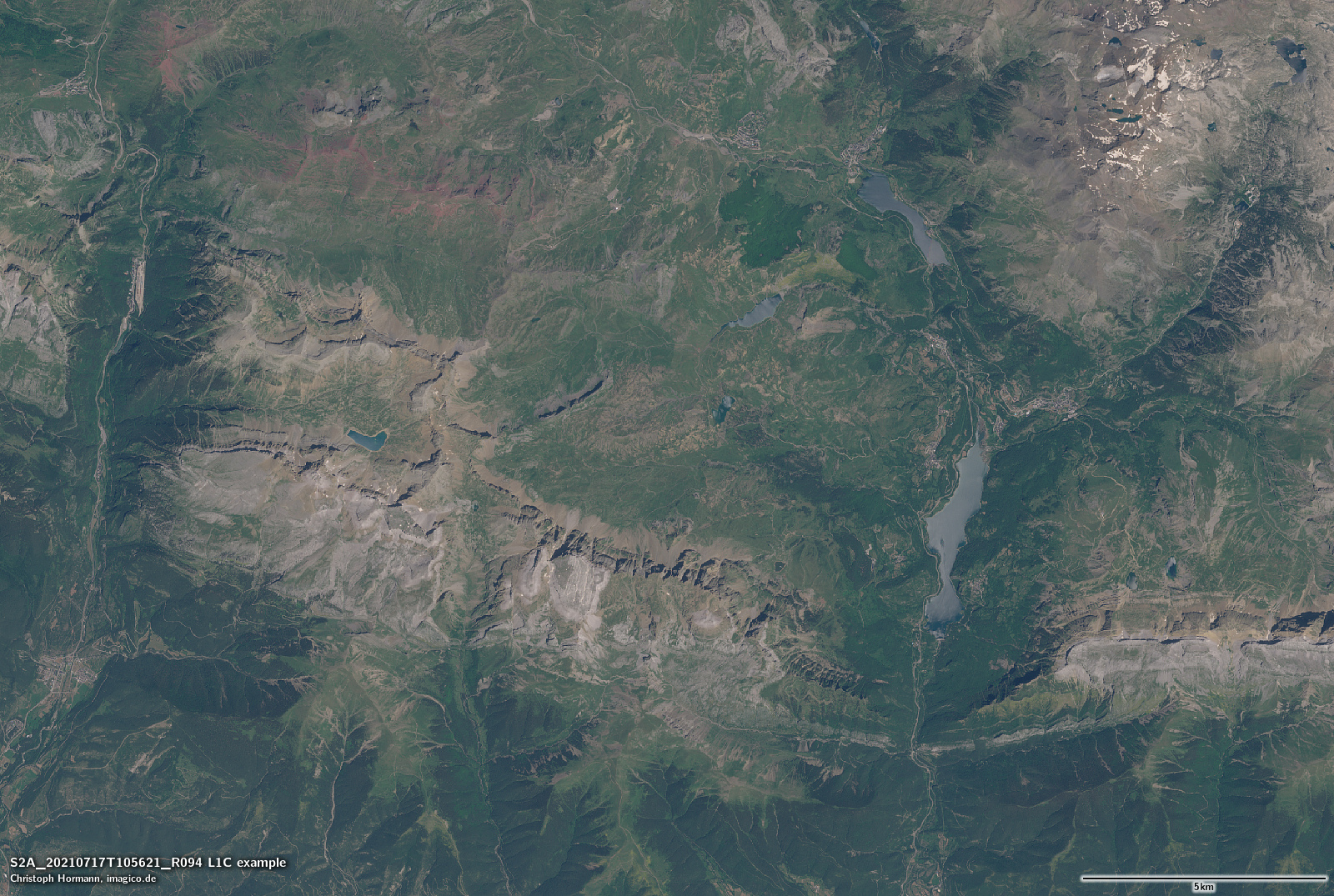
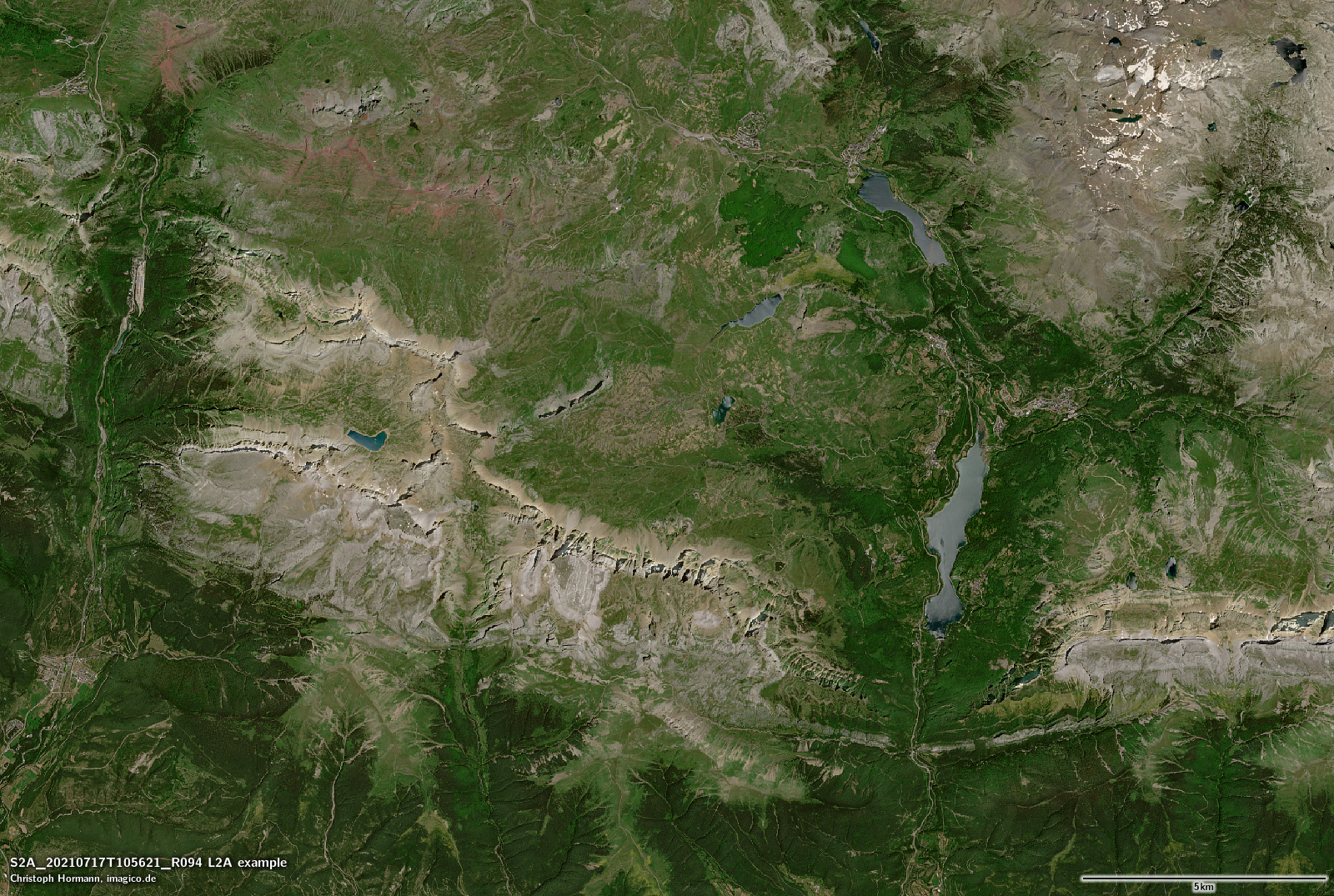
Die meisten erfahrenen Nutzer von Satellitenbildern werden verstehen, dass die L2A-Daten – wie ich sie charakterisiert habe – nur eine Schätzung des Oberflächen-Reflexionsgrades sind. Und während dies die Varianz aufgrund des variablen Einflusses der Erdatmosphäre reduzieren sollte, wird es auch zusätzliche Varianz in Form von verschiedenen Formen von Rauschen und systematischen und zufälligen Fehlern in die Schätzung einbringen. Was den meisten Datennutzern jedoch nicht bewusst ist, ist die Tatsache, dass die Sentinel-2-L2A-Daten auch versuchen, Beleuchtungsunterschiede (Die Schattierung) zu kompensieren, und dass diese Kompensation – um es ganz offen zu sagen – unglaublich schlecht ist. So schlecht, dass sie für Visualisierungszwecke praktisch unbrauchbar ist. Hier ein Beispiel – größere Version ist verlinkt:

S2A L1C von 2021-07-17
S2A L2A von 2021-07-17
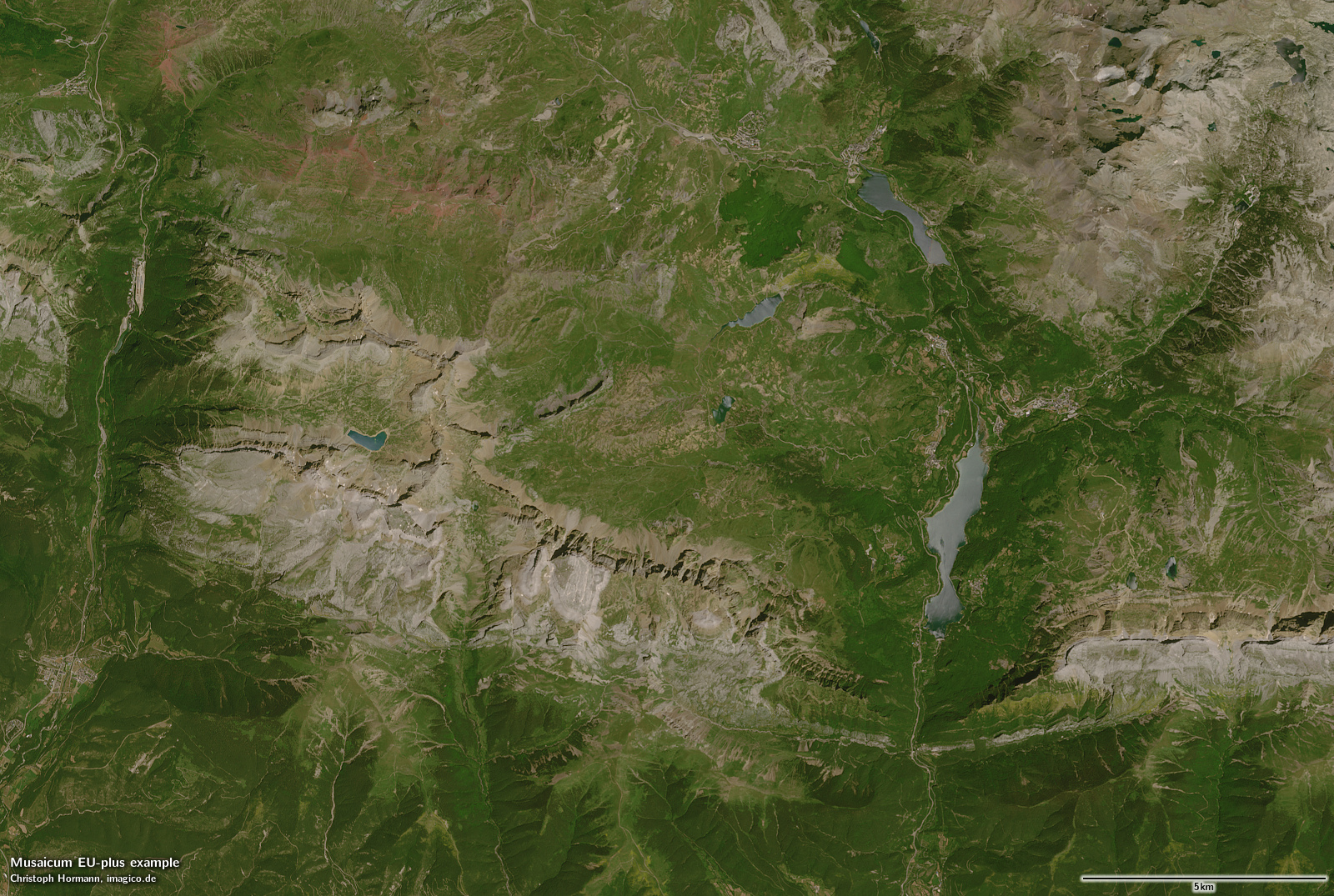
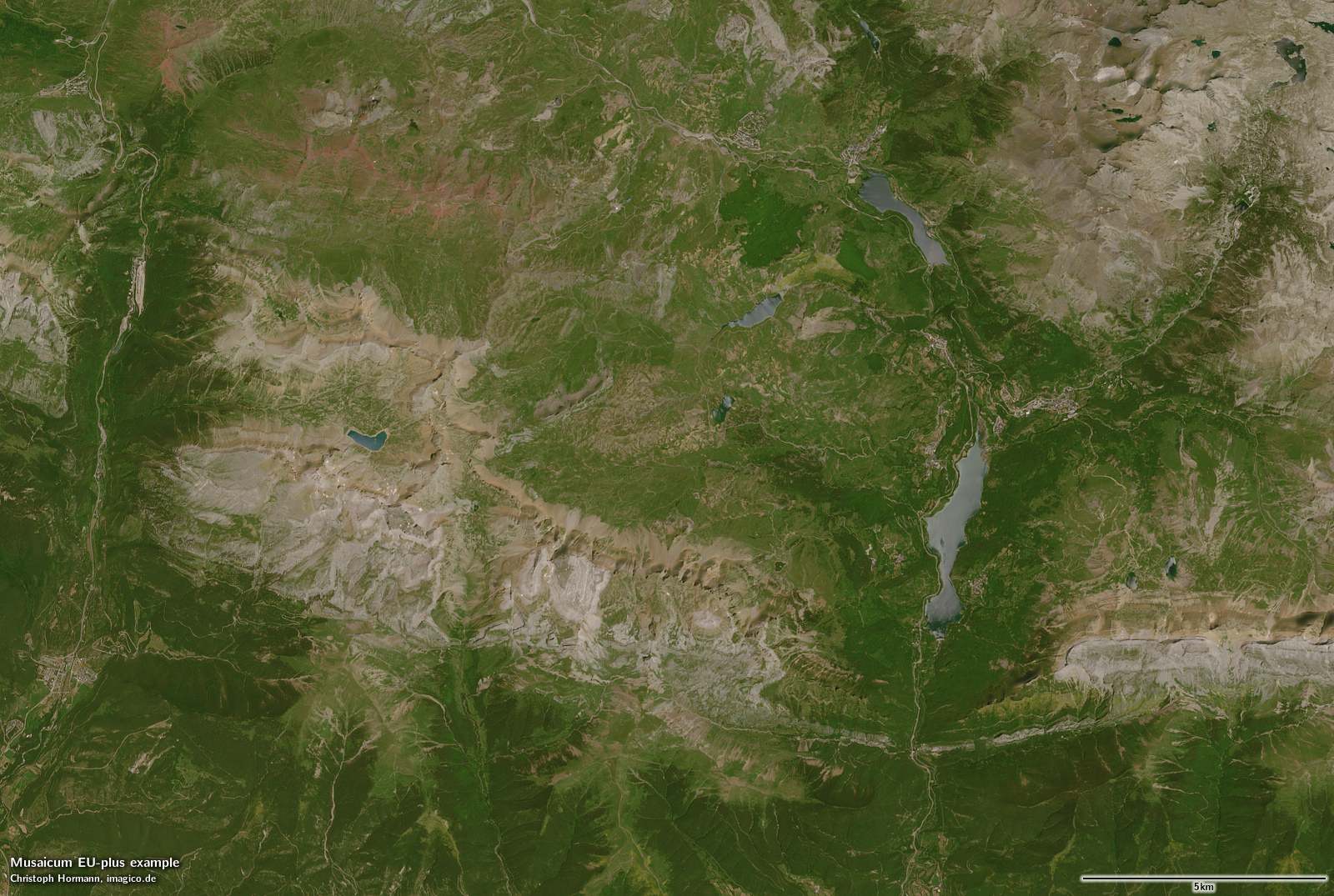
Zum Vergleich hier das neue Europa-Mosaik (das im Standard-Rendering Atmosphären-kompensiert, aber nicht Schattierungs-kompensiert ist) und meine eigene Schattierungs-kompensierte Version. Für den größten Teil des Beispielgebiets basiert das Mosaik auf der gleichen Aufnahme – mit Ausnahme des oberen rechten Bereichs, wo das Juli-Bild noch Schneereste enthält, so dass das Mosaik ein Bild aus einer späteren Jahreszeit verwendet.
Das neue Europa-Mosaik – Tena-Tal, Pyrenäen

Schattierungs-kompensierte Version
Der Farbunterschied insgesamt ist hier nicht der Hauptpunkt (die Farbdarstellung, in der ich die L1C/L2A-Daten dargestellt habe, ist etwas willkürlich). Der Hauptpunkt ist, dass die Beleuchtungskompensation in den L2A-Daten massiv überkompensiert, was dazu führt, dass die schattigen Hänge oft heller sind als die der Sonne zugewandten Hänge. Außerdem ist sie geometrisch ziemlich ungenau, was zu einer starken Betonung von Reliefkanten und zu erheblichen Mengen an hochfrequentem Rauschen führt.
Es scheint, dass einige Leute die Sentinel-2 L2A-Daten für Visualisierungsanwendungen verwenden. Das ist keine gute Idee. Sie sollten Schattierungs-kompensierte Bilder nur dann für Visualisierungen verwenden, wenn Sie genau wissen, was Sie tun, und in diesem Fall sollten Sie eine ordentliche Methode anwenden und nicht die Stümperei die von der ESA hier angeboten wird.
Ich habe die Frage der Schattierungs-Kompensation, insbesondere für die Verwendung beim 3D-Rendering, bereits früher erörtert. Eine Schattierungs-kompensierte Version ist auch für das Musaicum EU-plus verfügbar – aber ich hatte noch nicht die Zeit für eine ordentliche Evaluation. Sie ist auf Anfrage erhältlich.
Was bleibt
Wie ich bereits erwähnt habe, ist dies ein erster Versuch eines weitgehend automatisierten klassischen Mosaik-Prozesses. Wie so oft bei dieser Art von Arbeit bleiben viele Dinge während der Prozessentwicklung unklar und werden erst klar, wenn man den Prozess in großem Maßstab durchführt. Das mag ein wenig nach übermäßigem Perfektionismus klingen, wenn man bedenkt, dass die Ergebnisse ziemlich gut sind. Aber es geht nicht nur um die Qualität der Ergebnisse, sondern auch um die Robustheit und Effizienz des Prozesses. Als allgemeine Faustregel für ein Projekt wie dieses würde ich sagen: Es ist sinnvoll, nach der ersten Anwendung im großen Maßstab noch mal so viel Arbeit in die Prozessentwicklung zu stecken wie vorher, wenn man das Potenzial der verwendeten Methode voll ausschöpfen will.

Svartisen, Norwegen
Wie geht es jetzt weiter?
Eine Frage, die sicher einige meiner Leser stellen werden, ist die: Funktioniert das auch außerhalb Europas? Im Prinzip lautet die Antwort ja, aber es geht um mehr als nur darum, das ganze auf einem Haufen weiterer Daten laufen zu lassen. Ein nicht unerheblicher Teil der Entwicklungsarbeit, die in dieses Projekt geflossen ist, bestand in der Abstimmung und Anpassung der Methoden und Parameter an die spezifischen Gegebenheiten in Bezug auf das Klima und die Oberflächenbeschaffenheit, die in dem bearbeiteten Gebiet zu finden sind. Aus meiner Erfahrung mit der Green Marble weiß ich, dass die Vielfalt der verschiedenen Umgebungen auf der Erde größer ist, als man gemeinhin annimmt. Das muss berücksichtigt werden, und das war nicht Teil dieses Projekts.
Es gibt noch eine Reihe anderer Ergänzungen und Erweiterungen des Projekts, an denen ich gerne arbeiten würde, zum Beispiel steht die Erstellung einer Vegetationskarte, ähnlich der für verschiedene lokale Mosaike, auf der Liste. Und natürlich stellt sich im Laufe der Zeit die Frage nach der Aktualisierung des Mosaiks mit neueren Daten. Ich weiß nicht, ob und wann ich die Kapazität haben werde, all dies zu tun. Wenn Leser daran interessiert ist, die weitere Arbeit daran zu unterstützen, können sie sich gerne bei mir melden.
Die Produktbeschreibung und weitere Beispielbilder finden Sie auf der Musaicum EU-plus Produktseite.
Vielen Dank an die Geofabrik für die Kofinanzierung dieses Projekts. Sollten Sie Interesse an einem Kachel-Dienst auf Basis des Musaicum EU-plus oder der Green Marble haben, wird man Ihnen bei der Geofabrik gerne helfen. Wenn Sie an einer Lizenzierung des Bildes für andere Zwecke interessiert sind, können Sie mich gerne kontaktieren.

Tödi, Schweiz

Zakynthos, Griechenland